

- Install PyCharm, pip3, zsh

- 2. Create a folder where would contain the zip file to upload AWS afterward. It’s recommended to be the same function name to be deployed to AWS function. Eg. lambda_function
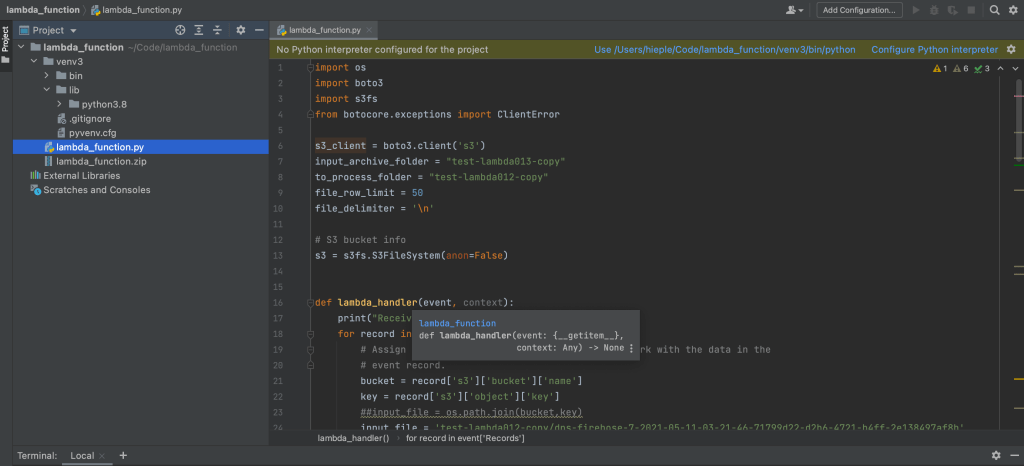
Add main python function file – which would be used to execute the code in AWS once uploaded – to the folder, this file will use the non-standard libraries to be installed. In my case: lambda_function.py file, with following content:
- 3. Create environment variable called venv3, using this command
virtualenv venv3



Important note: using pip3 instead of pip, otw the function won’t work and come up with this kind of error when running:

Here is how the folder structure looks like after the packages installation:

cd venv3/lib/python3.8/site-packages/

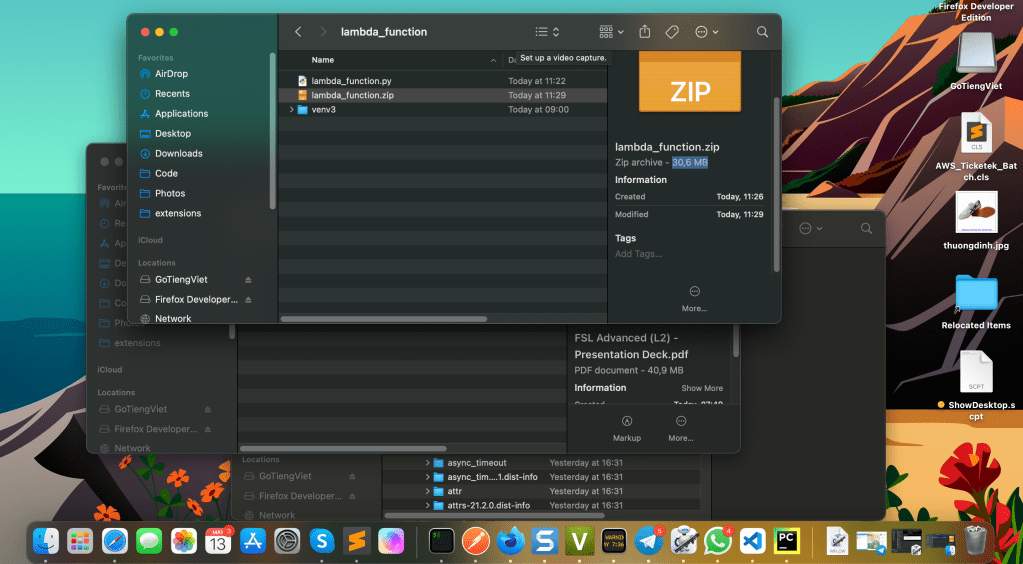
Zip the files and folder, in my case:
zip -r9 ${OLDPWD}/lambda_function.zip dateutil docutils jmespath s3fs s3transfer fsspec six.py
zip all libs in site-packages:
zip -r9 ${OLDPWD}/lambda_function.zip *

cd $OLDPWD
Add lambda_function.py file to the zip
zip -g lambda_function.zip lambda_function.py

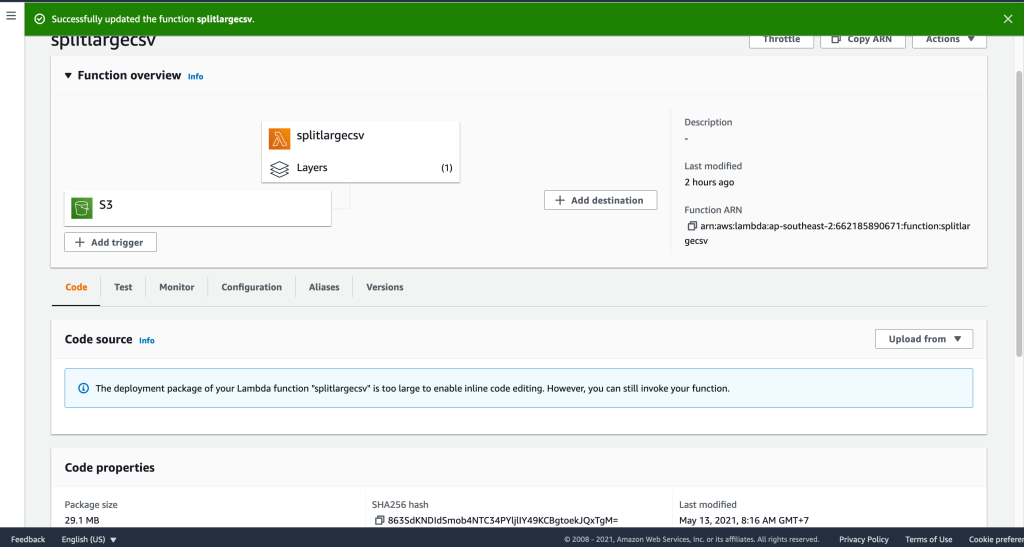
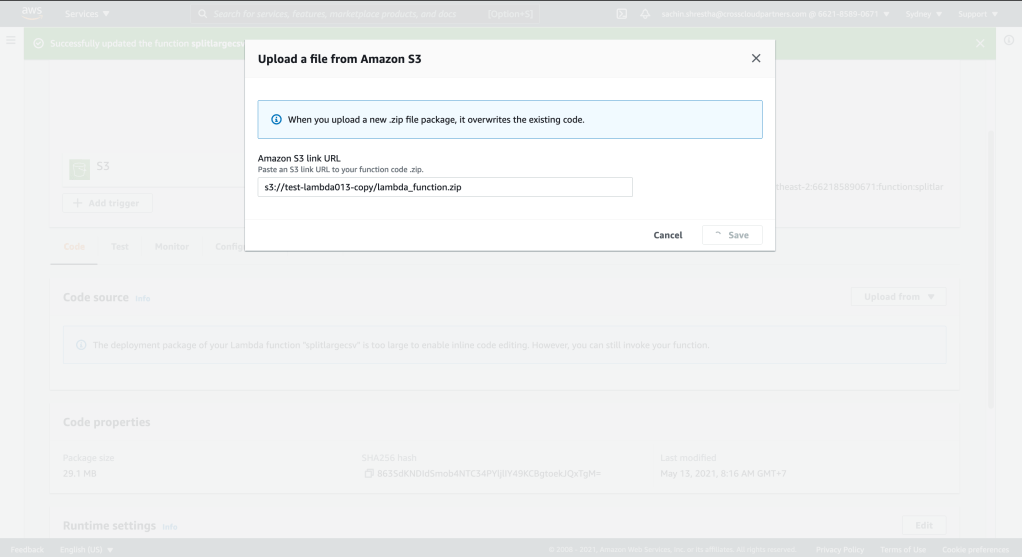
My case: zip file is greater than 30MB


Take a look at your function handler name, which normally cause the compiling error like above

This is important to avoid infinite/recursive split

Bonus
If everything is fine, but time out for long running task, you may encounter such error message:

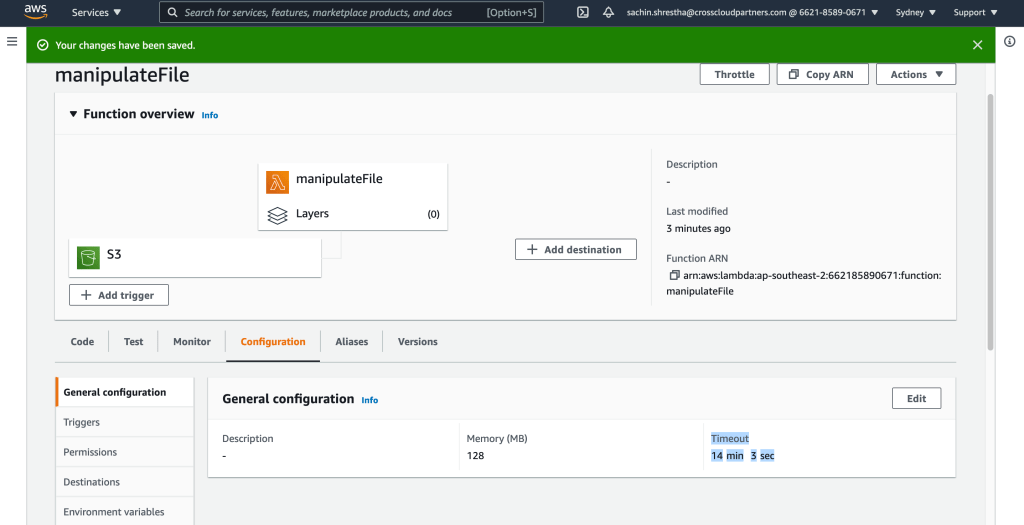
What you need to do is increase the time out of the lambda function, max 15 mins. Default: 3 secs.
Max time it recalls the function in case of time out is 3, and ends afterwards.
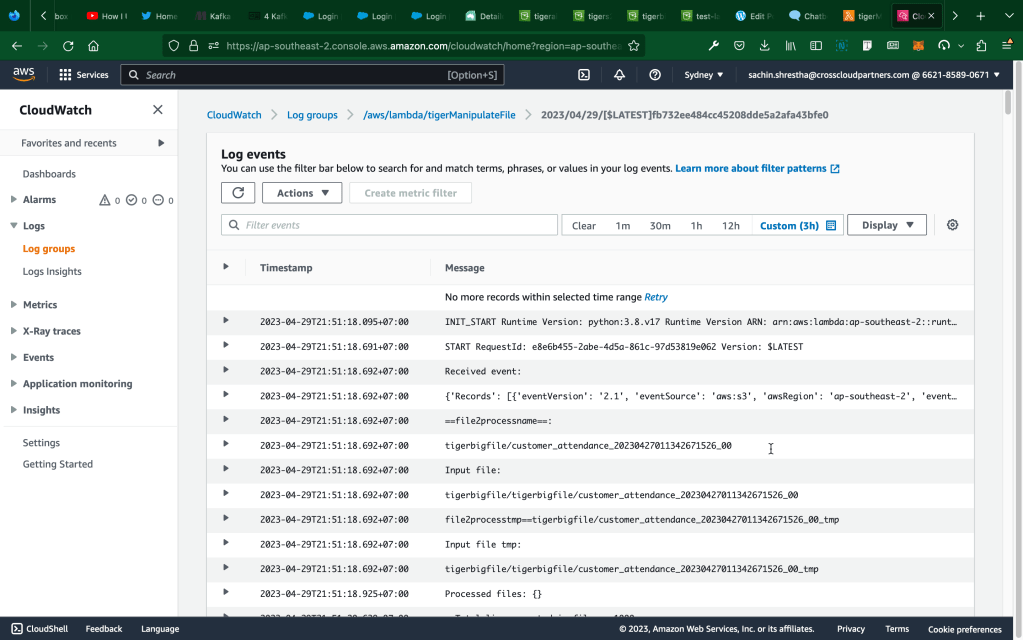
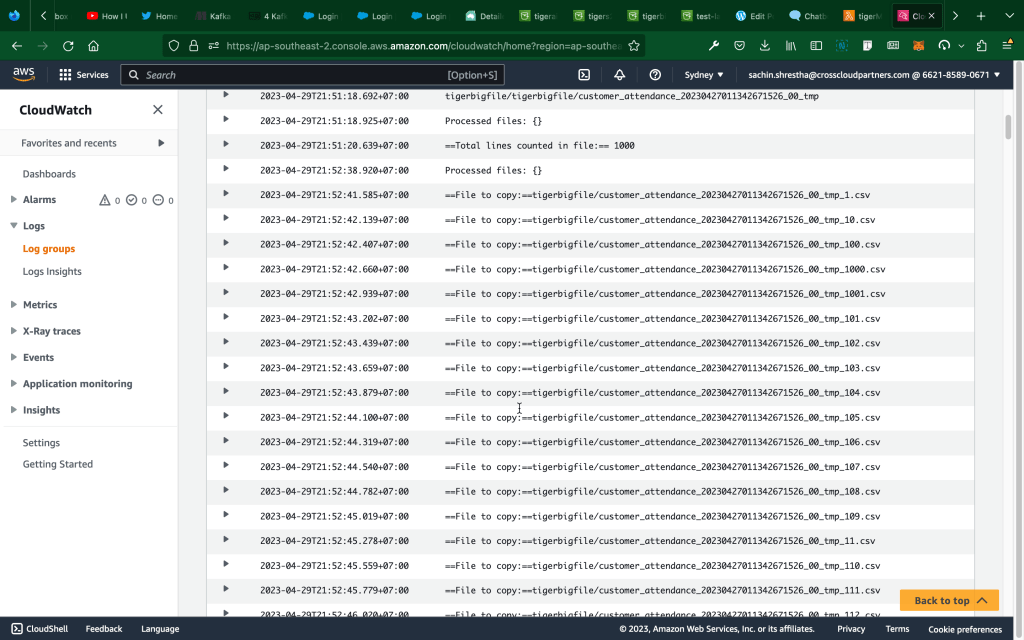
Log example:
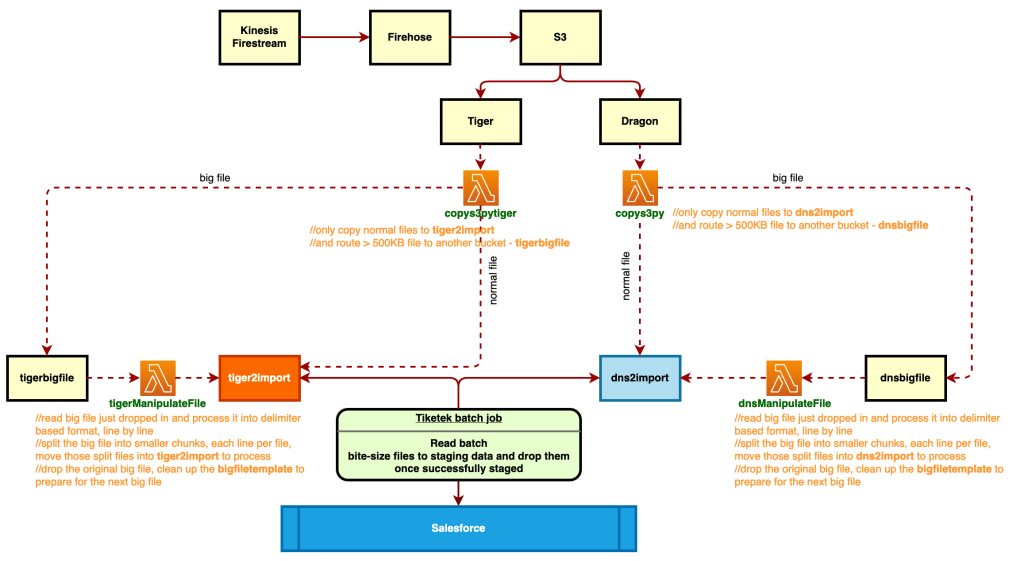
Final design
Sample code for copy function:
import json
import boto3
import os
import botocore
s3_client=boto3.client('s3')
s3 = boto3.resource('s3')
# lambda function to copy file from 1 s3 to another s3
def lambda_handler(event, context):
#specify source bucket
source_bucket_name=event['Records'][0]['s3']['bucket']['name']
#get object that has been uploaded
file_name = event['Records'][0]['s3']['object']['key']
#specify the target folder for files copied
#key='files2process/'+file_name
#specify the source of listening files to make decision
source_bucket_to_listen = 'dns-ticketek'
bucket = s3.Bucket(source_bucket_to_listen)
key = bucket.Object(file_name)
#print('==File size==', key.content_length)
#specify destination bucket
dest_bucket_bigfilename='dnsbigfile'
dest_bucket_bffolder='dnsbigfile'
destination_bucket_name='dns2import'
destination_bucket_folder='dns2import'
#specify from where file needs to be copied
copy_object = {'Bucket':source_bucket_name,'Key':file_name}
#response_contents = s3_client.list_objects_v2(Bucket=source_bucket_name).get('Contents')
#write copy statement
##This worked
#for rc in response_contents:
#'Size' returns in bytes
#If file size larger than or equal to 500KB
#filename = rc.get('Key')
#print('==File name==' + filename + ' and size: ', rc.get('Size'))
#if rc.get('Size') >= 500*1024:
if key.content_length >= 500*1024:
#print(f"Key: {rc.get('Key')}")
#Copy to the big file name folder
s3_client.copy_object(CopySource=copy_object,Bucket=dest_bucket_bigfilename,Key=file_name)
s3.Object(dest_bucket_bigfilename,dest_bucket_bffolder + '/' + os.path.basename(file_name)).copy_from(CopySource=copy_object)
s3.Object(dest_bucket_bigfilename,file_name).delete()
elif key.content_length < 500*1024:
#Copy normal files to destination folder
s3_client.copy_object(CopySource=copy_object,Bucket=destination_bucket_name,Key=file_name)
s3.Object(destination_bucket_name,destination_bucket_folder + '/' + os.path.basename(file_name)).copy_from(CopySource=copy_object)
s3.Object(destination_bucket_name,file_name).delete()
return {
'statusCode': 3000,
'body': json.dumps('File has been successfully copied')
}
Sample code for file split lambda function:
import os
import boto3
import s3fs
import base64
import json
import sys
import csv
from botocore.exceptions import ClientError
s3_client = boto3.client('s3')
# S3 bucket info
s3 = s3fs.S3FileSystem(anon=False)
s3_res = boto3.resource('s3')
# added
# s3_res = boto3.resource('s3')
##Important! Need to configure the lambda function time out to 14mins
def lambda_handler(event, context):
output = []
print("Received event: \n" + str(event))
for record in event['Records']:
# specify source bucket
source_bucket_name = event['Records'][0]['s3']['bucket']['name']
# get object that has been uploaded
file2processname = event['Records'][0]['s3']['object']['key']
print("==file2processname==: \n", file2processname)
#print("==file2processnamecut==: \n" + file2processname[14:len(file2processname)])
file2processnamecut = file2processname[14:len(file2processname)]
#dnsbigfile/dns-firehose-7-2021-05-11-03-21-46-71799d22-d2b6-4721-b4ff-2e138497af8b_tmp_21.csv
#input_file = 'test-lambda012/dns-firehose-7-2021-05-11-03-21-46-71799d22-d2b6-4721-b4ff-2e138497af8b'
#input_file_tmp = 'test-lambda012/tmp2readfull'
#input_file = 'dnsbigfile/dnsbigfile/' + file2processname
input_file = 'dnsbigfile/dnsbigfile/' + file2processnamecut
print("Input file: \n" + input_file)
#Create empty file named after recently landed file plus _tmp suffix
##s3_client.put_object(Bucket='dnsbigfile', Key='dnsbigfile/' + file2processname + '_tmp')
#file2processtmp = file2processname + '_tmp'
file2processtmp = file2processnamecut + '_tmp'
print("file2processtmp==" + file2processtmp)
#input_file_tmp = 'dnsbigfile/dnsbigfile/tmp2readfull'
input_file_tmp = 'dnsbigfile/dnsbigfile/' + file2processtmp
print("Input file tmp: \n" + input_file_tmp)
response_contents = s3_client.list_objects_v2(Bucket=source_bucket_name).get('Contents')
for rc in response_contents:
# 'Size' returns in bytes
# If file size larger than or equal to 500KB
filename = rc.get('Key')
if rc.get('Size') >= 500*1024:
# Read the file, write to temp file with \n added
f = s3.open(input_file,'r')
a = f.read()
#print("==File Content== \n" + a.replace("}{", "}\n{"))
g = s3.open(input_file_tmp, 'w')
g.write(a.replace("}{", "}\n{"))
f.close()
g.close()
# Split the temp file just added the \n between }{ into several files, each line per file
num = sum(1 for line in s3.open(input_file_tmp))
print("==Total lines counted in file:==", num)
# This is to avoid max size limit
maxInt = sys.maxsize
while True:
# decrease the maxInt value by factor 10
# as long as the OverflowError occurs.
try:
csv.field_size_limit(maxInt)
break
except OverflowError:
maxInt = int(maxInt / 10)
## Split the ready file
sorting = True
num_of_lines_each = 1
hold_lines = []
with s3.open(input_file_tmp, 'r') as csvfile:
for row in csvfile:
hold_lines.append(row)
outer_count = 1
line_count = 0
while sorting:
count = 0
increment = (outer_count - 1) * num_of_lines_each
left = len(hold_lines) - increment
#file_name = 'test-lambda012/tmp2read_full_' + str(outer_count * num_of_lines_each) + '.csv'
file_name = input_file_tmp + '_' + str(outer_count * num_of_lines_each) + '.csv'
hold_new_lines = []
if left < num_of_lines_each:
while count < left:
hold_new_lines.append(hold_lines[line_count])
count += 1
line_count += 1
sorting = False
else:
while count < num_of_lines_each:
hold_new_lines.append(hold_lines[line_count])
count += 1
line_count += 1
outer_count += 1
with s3.open(file_name, 'w') as next_file:
for row in hold_new_lines:
next_file.write(row)
## Move all split files to dns2import, move to dnsfilessplit first to test
response_contents2 = s3_client.list_objects_v2(Bucket='dnsbigfile').get('Contents')
# destination_bucket_name = 'dnsfilessplit'
# destination_bucket_folder = 'dnsfilessplit'
destination_bucket_name = 'dns2import'
destination_bucket_folder = 'dns2import'
strcontained = '_tmp_'
for rc2 in response_contents2:
filename = rc2.get('Key')
filesize = rc2.get('Size')
if filename.find(strcontained) != -1:
copy_object = {'Bucket': 'dnsbigfile', 'Key': filename}
print("==File to copy:==" + filename)
s3_client.copy_object(CopySource=copy_object, Bucket=destination_bucket_name, Key=filename)
s3_res.Object(destination_bucket_name, destination_bucket_folder + '/' + os.path.basename(filename)).copy_from(CopySource=copy_object)
s3_res.Object(destination_bucket_name, filename).delete()
#Delete the file after copying it to the target folder
s3_res.Object('dnsbigfile', filename).delete()
## To do: delete the big file after done reading successfully
elif filesize >= 500*1024:
s3_res.Object('dnsbigfile', filename).delete()